Generative Benchmarking
2025-04-07
This was the first technical report I published at Chroma. Generative benchmarking addresses the limitations of public benchmarks with custom evals that reflect your data.
Video walkthrough
A core limitation of current benchmarks is that they often fail to accurately reflect the actual use cases of their evaluated models. Despite this, there exists a common misconception that strong performance for a model on a public benchmark directly generalizes to comparable real-world performance.
A model’s performance on a public benchmark is often inflated by polished datasets that lack the ambiguity of production scenarios, as well as potential memorization of the retrieval task from seeing the benchmark already in training.
We present a query generation method for evaluating retrieval systems that addresses the limitations of publicly available benchmarks. We focus on aligning our generated queries with the ground truth, across public datasets and real production data from Weights and Biases. Alongside these demonstrations, we provide the full codebase for generating a benchmark on any set of documents.
Method
We present our generative benchmarking method which follows two key steps:
- Document filtering - use an aligned LLM judge and user-provided context to filter for documents that users will realistically query.
- Query generation - using user-provided context and example queries, steer LLM generation to generate realistic queries.
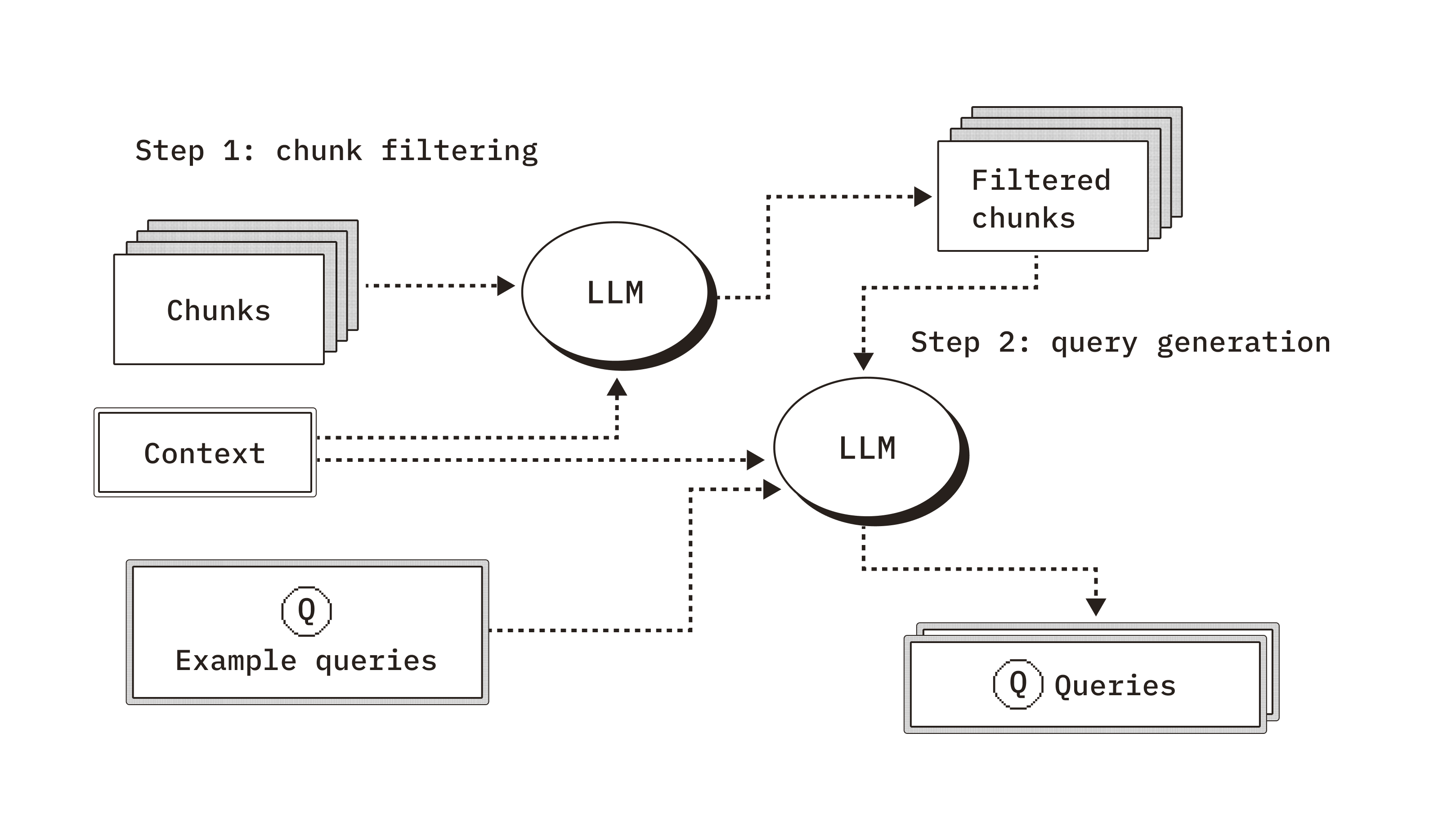
2-step process
Representativeness
A core part of our research is validating that our generated queries are truly representative of real user queries. We collaborate with Weights and Biases to apply generative benchmarking to their data, which includes the documentation and production queries from their technical support bot.
We experiment with various query generation methods to capture the characteristics of real user queries in production settings; filtering documents for quality, and steering queries. We demonstrate that our generated queries yield model performance metrics that closely align with those of the real queries and capture performance differences that MTEB fails to reflect.
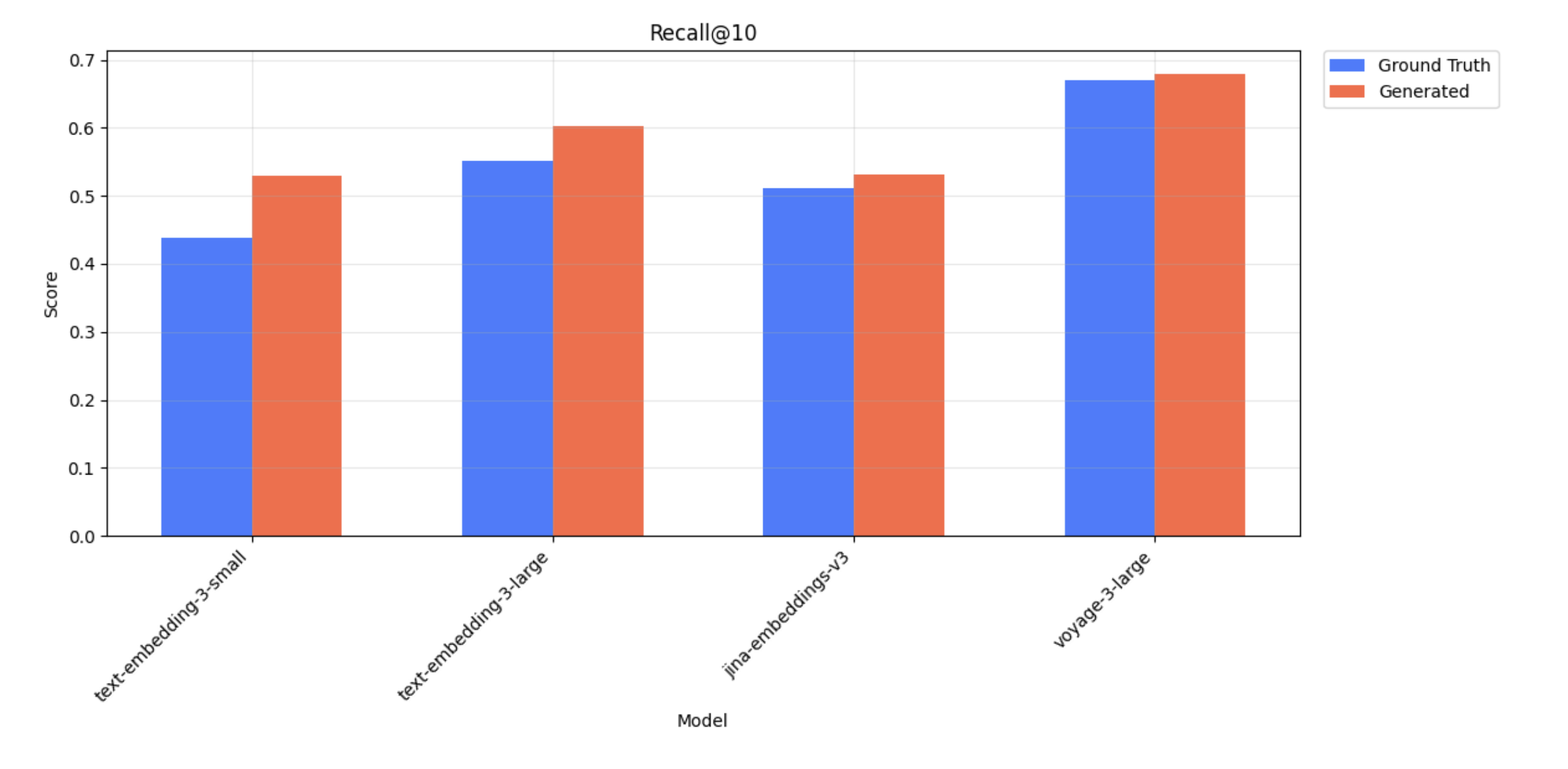
Recall@10 scores for ground truth and generated queries on Weights and Biases data
With each embedding model, we perform the retrieval task for ground truth queries and generated queries, then compare the metrics between the two. For both retrieval tasks, we observe similar relative performance across embedding models. For example, voyage-3-large has a higher Recall@10 score when compared to text-embedding-3-small for both ground truth and generated queries.
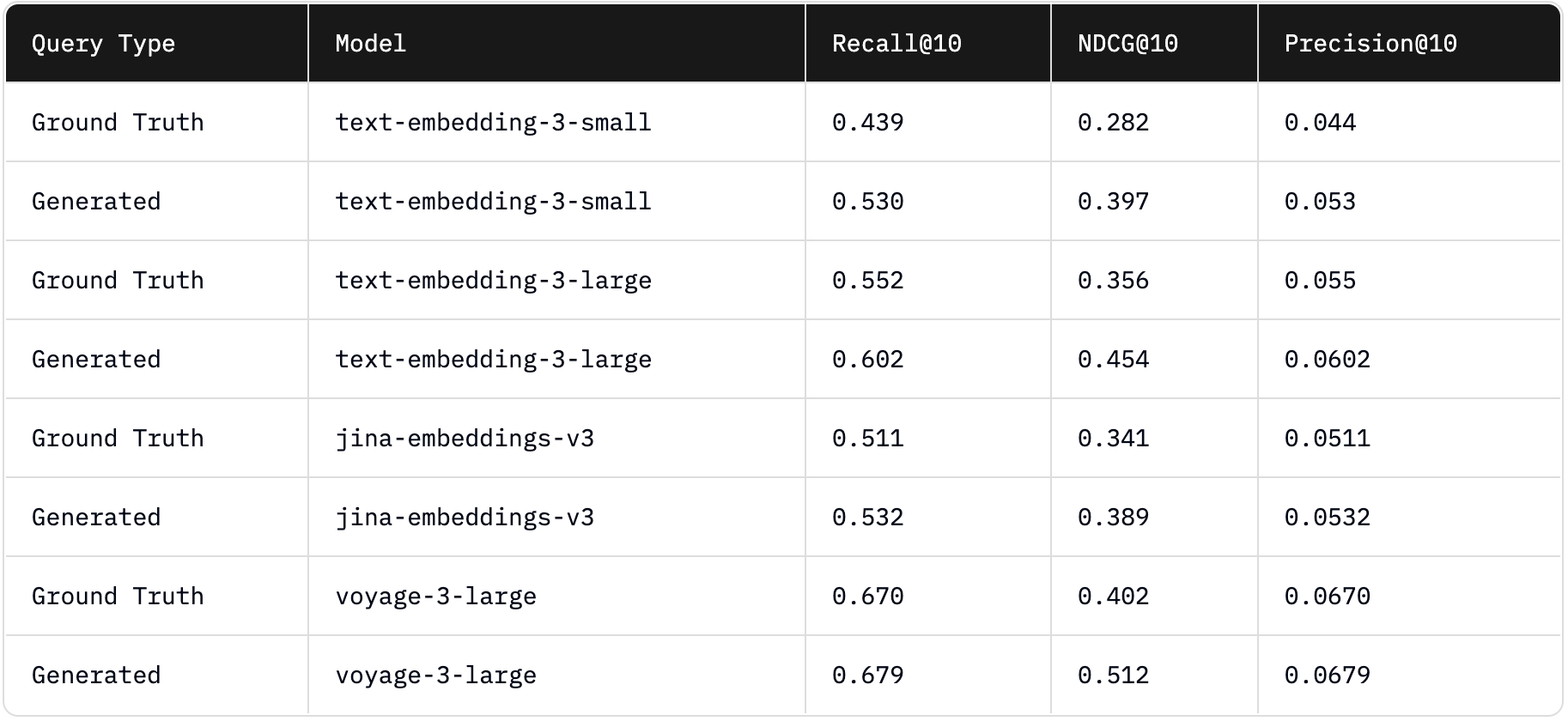
Metrics for ground truth and generated queries. We observe a shift between the ranking for text-embedding-3-small vs jina-embeddings-v3 for NDCG@10; however, the performance scores are close in this case and we generally see consistent rankings.
The generated queries often exhibit higher specificity and relevance to the provided target document compared to the ground truth queries, which naturally boosts retrieval performance across all embedding models. Thus, we focus on the relative evaluation of performance between embedding models as a proxy for representativeness rather than on absolute values. These relative differences produce consistent rankings of embedding models regardless of whether the queries were generated—which reflects the primary goal in real use cases where embedding models are selected based on relative performance.
We also highlight a discrepancy with MTEB scores. Our results show that jina-embeddings-v3 exhibits lower retrieval performance than text-embedding-3-large—despite jina-embeddings-v3 consistently outperforming text-embedding-3-large across all MTEB English tasks. This reinforces our central claim on how performance on public benchmarks such as MTEB does not always translate to real-world performance.
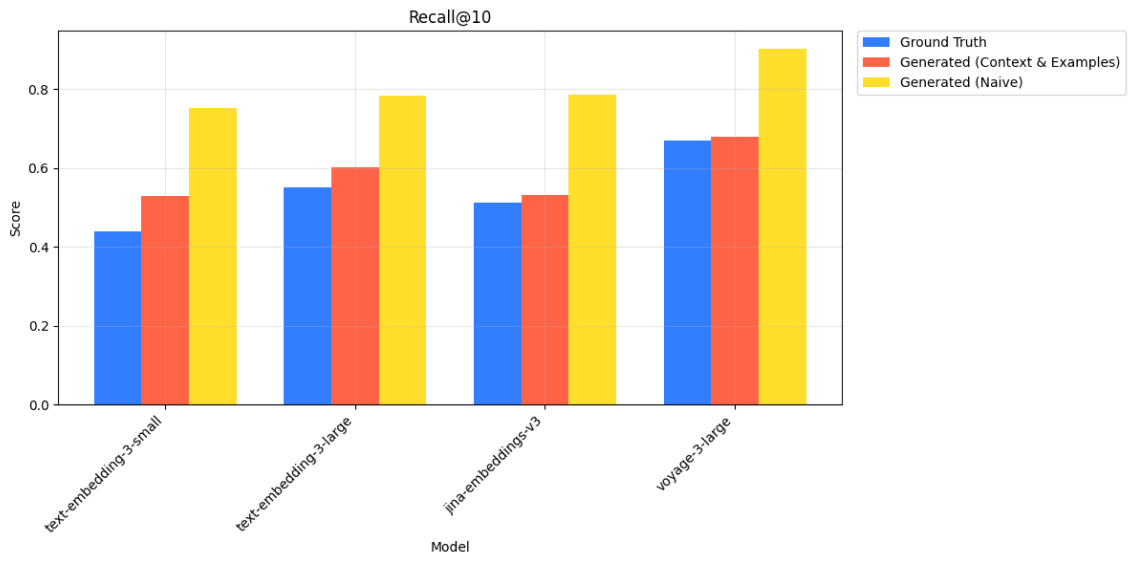
Recall@10 scores for ground truth, generated (with context & examples), and naively generated queries on Weights and Biases data
We also compare our generated queries with context and examples against naively generated queries (lacking any context or examples in generation). While these naive queries also maintained similar rankings among embedding models in this case, they yielded higher retrieval metrics than the ground truth. This could misleadingly suggest better performance compared to what would be expected in a real production environment.
In contrast, our query generation method with context and examples not only preserved the ranking of embedding models but also produced metrics that closely matched those from ground truth queries. This highlights an important distinction: representative queries are valuable not just for comparing models, but for approximating real-world performance. By better reflecting the characteristics of actual user traffic, our method offers a more accurate benchmark.
Final Notes
Strong performance on a public benchmark for a given embedding model does not guarantee comparable performance for your specific production pipeline. Custom evals base on your data provide a more accurate reflection of how your retrieval system is performing in production.
While we call this approach generative benchmarking, it is not fully automated. Building useful evals still requires manual iteration: aligning your LLM judge and looking at your data to understand where and why your system fails. This method gives you a good foundation to start from, but truly meaningful evaluation requires human involvement.
Features
If you want to hear me talk more about generative benchmarking, check out my TWIML AI podcast episode and talk in Jason Liu's RAG course.
This work was also featured in projects like Corner's semantic search evaluation.