How GPT Learns Layer by Layer
2025-01-13
An exploratory project I did with my friends to learn about mechanistic interpretability. We analyze OthelloGPT, a GPT-based model trained on Othello gameplay, as a controlled testbed for studying representation learning.
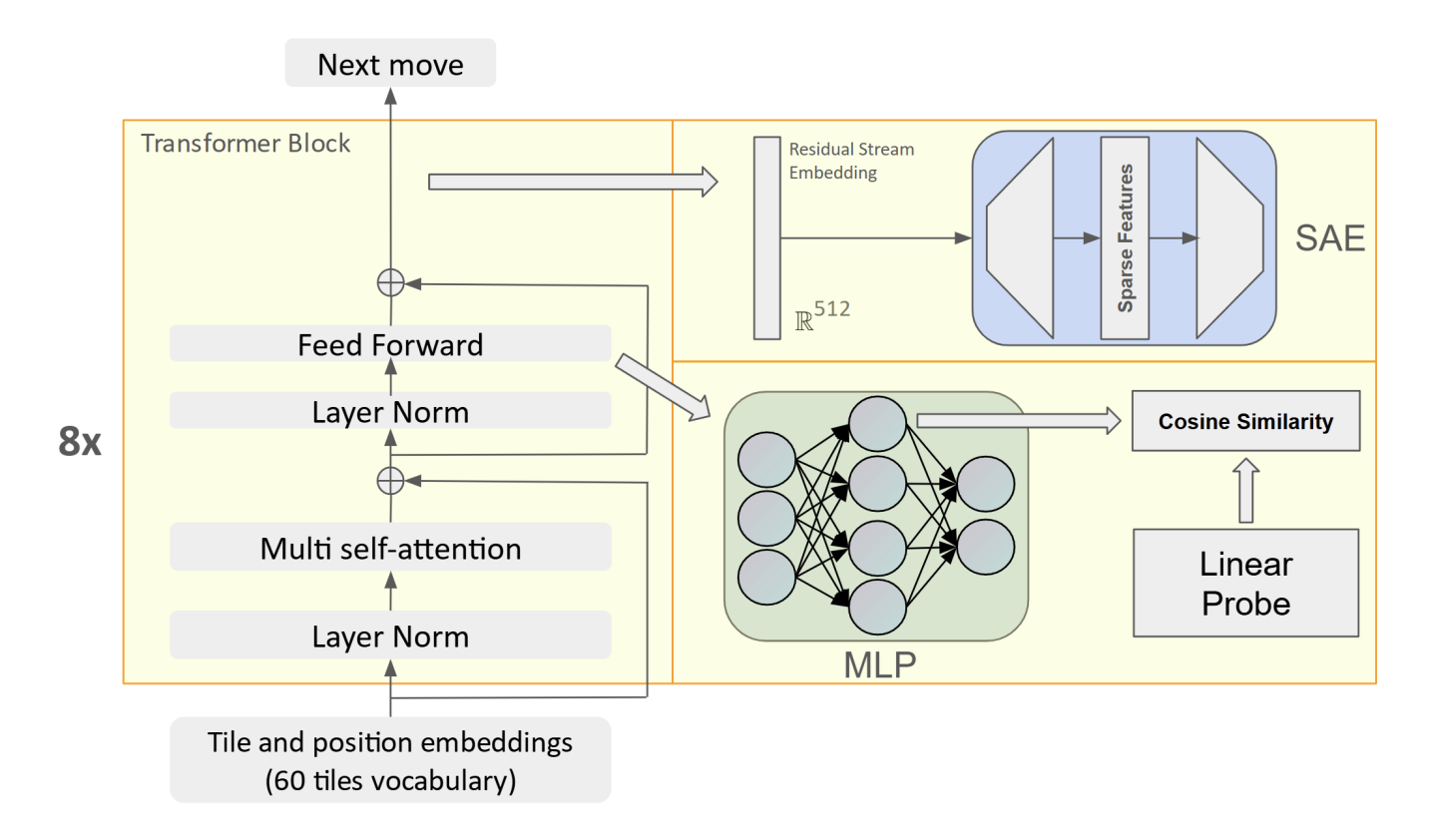
Overview of our experiment
Despite being trained solely on next-token prediction with random valid moves, OthelloGPT shows meaningful layer-wise progression in understanding board state and gameplay. Early layers capture static attributes like board edges, while deeper layers reflect dynamic tile changes. To interpret these representations, we compare Sparse Autoencoders (SAEs) with linear probes, finding that SAEs offer more robust, disentangled insights into compositional features, whereas linear probes mainly detect features useful for classification.
We've open-sourced our code to replicate our results and build onto this work.
Note: This was our first attempt at mechnaistic intrepretability—we are not experts in this field and just wanted to share some interesting findings we had.
Sparse Autoencoders (SAEs) vs Linear Probes
We compare Sparse Autoencoders (SAEs) and linear probes to analyze the learned representations. Our experiments show that SAEs uncover more distinctive and disentangled features, particularly for compositional attributes, whereas linear probes primarily identify features that act as strong correlators to classification accuracy.
What are Sparse Autoencoders?
Sparse Autoencoders (SAEs) are neural networks trained to transform model activations into a sparse set of features that reconstruct the original input. Unlike standard autoencoders—which reduce dimensionality—SAEs expand the hidden layer and encourage sparsity through an L1 penalty, so that only a small number of features activate at once.
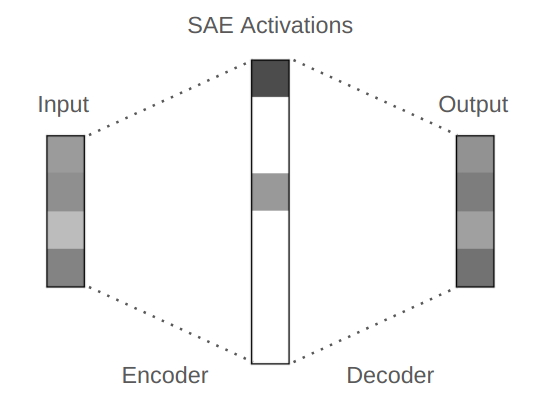
Diagram of Sparse Autoencoder. Note that the intermediate activations are sparse, with only 2 nonzero values. Source
Each activation corresponds to a learned feature (i.e. tile color), and sparsity helps ensure that these features are both distinct and interpretable. Instead of all features lighting up at once, the model is forced to choose the most relevant ones.
We apply SAEs to the residual stream of OthelloGPT to isolate compositional attributes of board state. Because most features remain inactive for any given input, the ones that do activate often correspond to clean, isolated concepts which make it possible to associate semantic meaning with specific neurons.
What are Linear Probes?
Linear probes are simple classifiers trained on frozen model activations to assess what information is linearly accessible at different layers. Given a hidden representation from OthelloGPT, we train a probe to predict whether a specific tile is empty, belongs to the player, or belongs to the opponent.
While linear probes are useful for evaluating representational capacity, they provide limited insight into how those features are structured. They tend to detect whatever is most predictive for a task—even if it's entangled with other features—making them better suited for classification rather than interpretation.
Comparison
Linear probes are effective at measuring what features a model encodes, but not how those features are organized. They highlight what’s linearly decodable, which often lead to blending together correlated attributes. In contrast, SAEs recover sparse, disentangled components of the representation, making it easier to assign semantic meaning to individual features.
Layer by Layer Analysis
We examine each layer of Othello-GPT, tracking two key gameplay concepts: tile color and stability. Tile color refers to the state of each board position—whether it's empty, occupied by the player, or by the opponent. Stability is defined as whether a tile can be flipped for the remainder of the game; stable tiles, such as corners or anchored edges, remain fixed and represent longer-term control over the board.
Linear probe accuracy increases with depth, suggesting that deeper layers encode progressively stronger predictors for classification. However, they fail to reveal distinct or compositional features per layer. SAEs address this by disentangling activations into sparse, interpretable bases, providing deeper insights into the features learned at each layer.
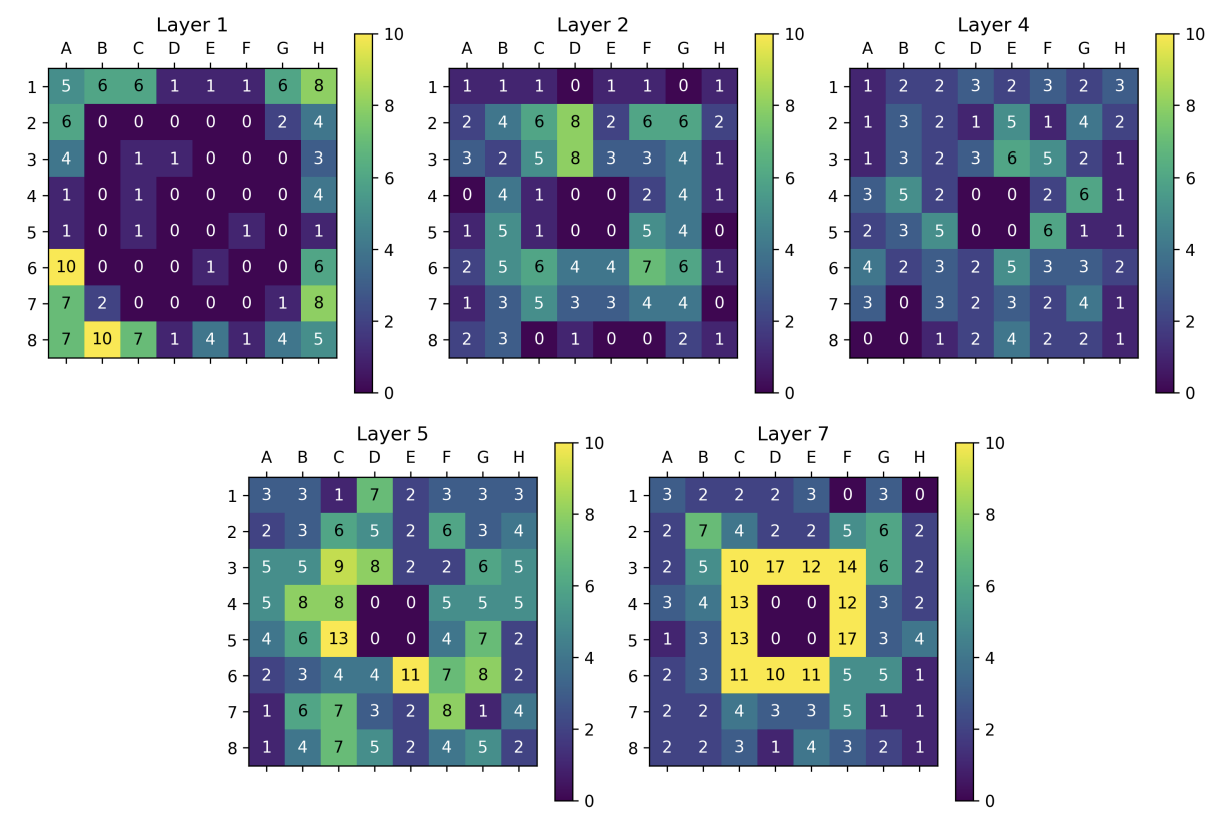
Linear Probe tile color activation maps
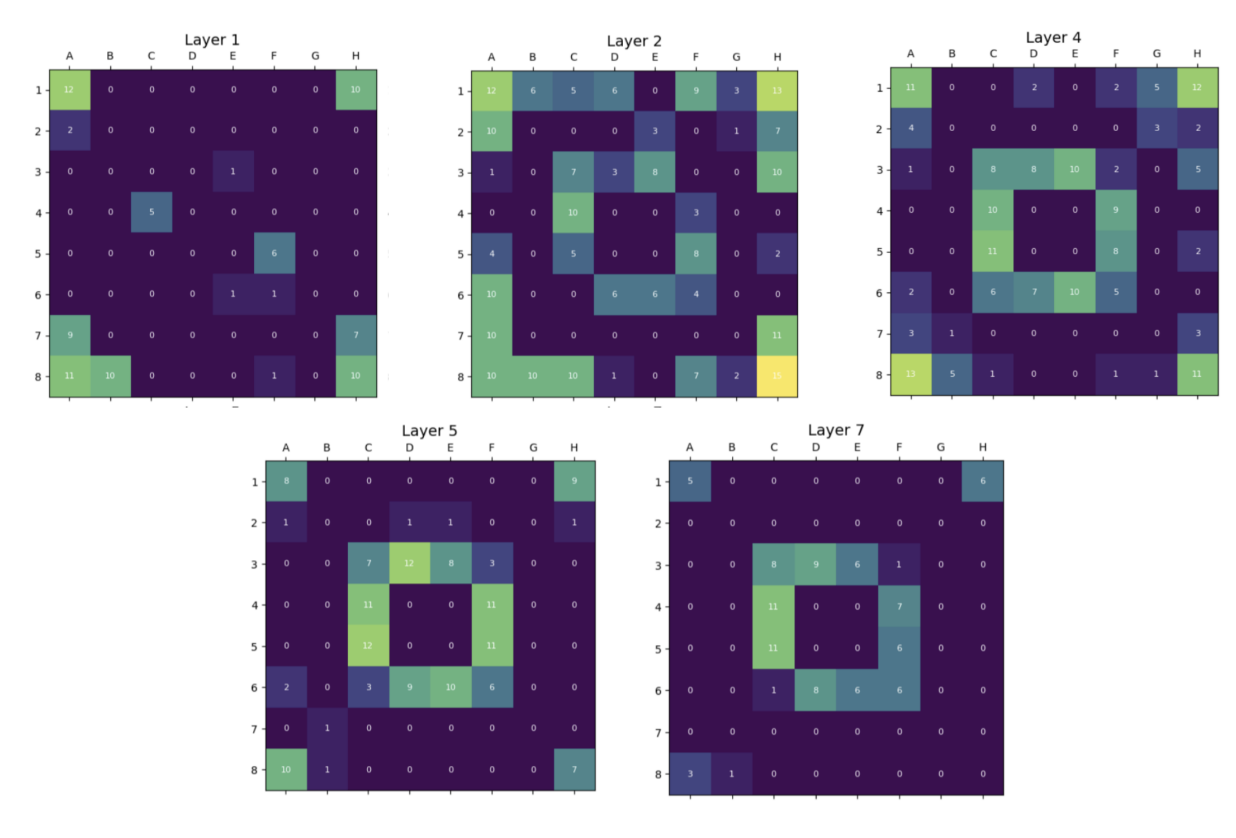
SAE tile color activation maps
These results reveal distinct differences in how SAEs and linear probes learn features from the board. SAE visualizations highlight clear and structured patterns, such as strong activations at corner and edge tiles in layer 1, indicating that the model captures the board’s shape early on. As we progress to Layers 2 and 4, SAEs show more dynamic changes, with activations concentrated in the central tiles and along the edges. This suggests the SAEs are not only learning positional importance but could also capturing the evolving dynamics of central tiles, which tend to flip frequently as the game progresses.
These results are aggregated across 10 random seeds, demonstrating the robustness and consistency of SAEs in identifying meaningful features. In contrast, the linear probe visualizations show more dispersed activations across the board. While individual tiles are well-classified, the activations lack the clear structural patterns seen in SAEs.
SAE tile stability activation maps
When analyzing tile stability, we observe that the strongest feature activations appear in the middle of the board—specifically layers 2 through 4. Earlier layers do not yet capture this long-range concept, while later layers likely reallocate capacity to downstream objectives like move prediction.
Final Notes
We analyzed the progression of learned features in OthelloGPT, revealing a hierarchical structure in its internal representations. Specifically, we observe that different layers in OthelloGPT focus on distinct aspects of gameplay: some capture structural attributes like board shape and edges, while others appear to encode dynamic features such as tile flips and shifts in board state.
By comparing the capabilities of sparse autoencoders (SAEs) and linear probes, we established that SAEs excel at uncovering more distinctive and disentangled features, particularly for compositional and interpretable attributes. In contrast, linear probes tend to highlight features that serve as strong correlators for classification tasks. Through these methods, we decoded features related to tile color and stability, offering a framework for understanding how GPT-based models and transformers construct and organize their internal representations.
Features
This project was mainly for our own learning purposes, but it ended up reaching some people which was cool to see.
Our work was cited in an Adobe Research paper and featured in some videos.